readpapers in shixi
[TOC]
lora
解决了如今语音识别等模型过大,需要频繁进行fine tune的问题
- 原本设计用于语音模型的微调
- 它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到Transformer架构的每一层,大大减少了下游任务的可训练参数的数量
- https://github.com/microsoft/LoRA
- https://zhuanlan.zhihu.com/p/612992813 stable diffusers各模型优化方法解读
主要相关方法
看出了一些端倪
AIGC任务分为两个网络:text_embedding模块和Diffusion Model,会有一些模型将这两个模块分别加载。但是在webui中,为合并加载,应当使用只在stable diffusion模块中加入影响的Lora模型进行训练。
dreambooth
- 直接在原本大模型后插入SKS小网络优化,微调参数。
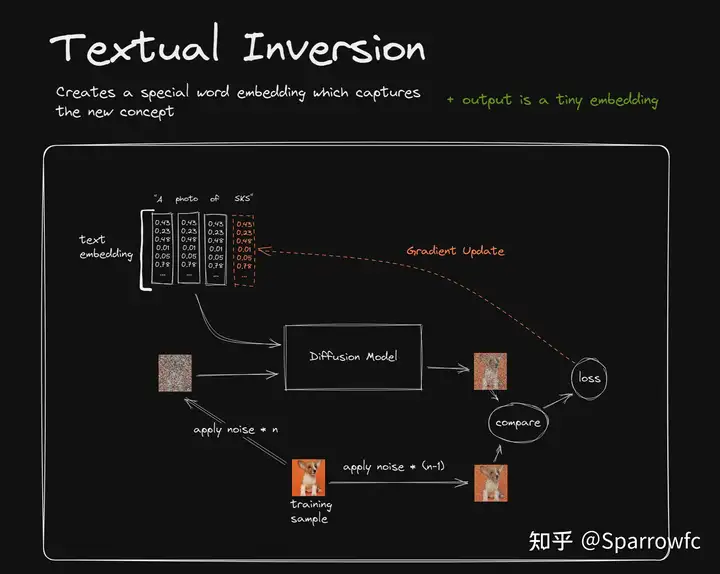
lora
注意,只是在text_embedding后加入一个小模块
在基础模型sd的transformer层之间插入秩分解矩阵,固定原本基础模型的参数。
好处在于可以得到一个较小的lora微调模型。无论是传播还是使用都方便
https://civitai.com/ lora模型站
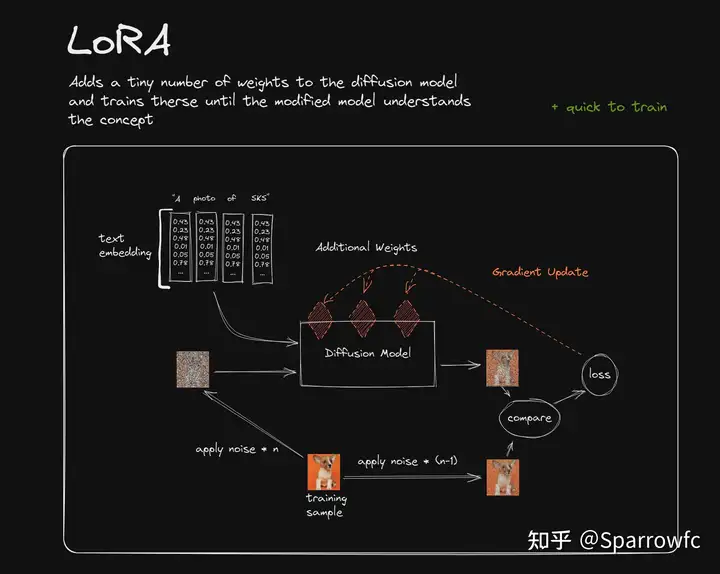
Hypernetwork
- 基本原理和lora相同,输出模型为全部的模型,即transformer块间加入微调层的大模型
lora
提出LoRA,一种有效的自适应策略,既没有引入推理延迟,也没有减少输入序列长度,同时保持高模型质量。重要的是,当作为服务部署时,通过共享绝大多数模型参数,它允许快速任务切换。虽然我们关注的是Transformer语言模型,但所提出的原则通常适用于任何具有密集层的神经网络。
High-Resolution Image Synthesis with Latent Diffusion Models
作者:Ludwig Maximilian University of Munich & IWR,慕尼黑大学
https://github.com/CompVis/latent-diffusion
我们的潜在扩散模型(ldm)在图像修补和类条件图像合成方面取得了新的最先进的分数,并在各种任务上获得了极具竞争力的性能,包括文本到图像合成,无条件图像生成和超分辨率,同时与基于像素的DMs相比,大大降低了计算需求。
PCAT: Functionality and Data Stealing from Split Learning by Pseudo-Client Attack
一种split learning攻击方法
现有方法需要白盒攻击,并只对浅层网络有效
思路在于生成一个类客户机模型,窃取客户机的功能
创新
- 可用于split learn 的各种结构
- 不需要得到网络结构
- 攻击对于服务器是透明的,行为与正常相同
- 只需要少量的原始数据
split learning

- split learning:多个常规算力节点(Alices)+一个超级算力节点(Bob)。核心思想是各方在不泄露原始数据的情况下,共同训练一个完整的模型,同时将模型中计算负载较高的部分安排在Bob节点。对Split Learning的介绍一般是基于分布式计算架构SplitNN进行展开。
- 联邦学习:分布式计算,多方提供部分数据集,地位相同
看不懂这个
联邦学习 (federated learning algorithm)
- 服务器是诚实但好奇的。
- 攻击形式:成员推理攻击、模型反演/数据重构攻击和属性推理攻击。可以攻击获得训练图像和模型权重
- 可以使用梯度模糊,加入高斯噪声等方法防御攻击,梯度压缩[61],差分私有训练[62],和表示扰动[66]。
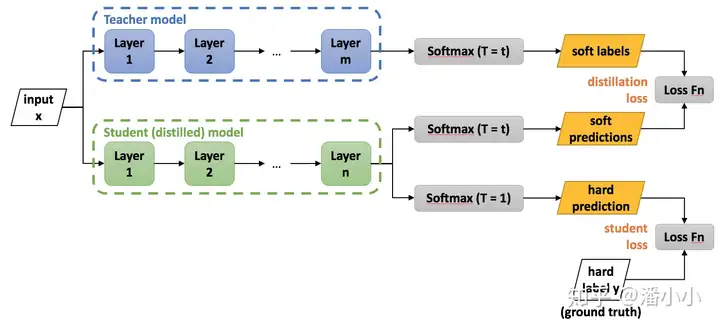
knowledge distillation(知识蒸馏)
https://zhuanlan.zhihu.com/p/102038521
模型压缩方法,是一种基于“教师-学生网络思想”的训练方法。
KD:就是将已经训练好的模型包含的知识(”Knowledge”),蒸馏(“Distill”)提取到另一个模型里面去。
可以用于模型的轻量化,类似的还有模型剪枝
模型就像一个容器,训练数据中蕴含的知识就像是要装进容器里的水。当数据知识量(水量)超过模型所能建模的范围时(容器的容积),加再多的数据也不能提升效果(水再多也装不进容器),因为模型的表达空间有限(容器容积有限),就会造成underfitting;而当模型的参数量大于已有知识所需要的表达空间时(容积大于水量,水装不满容器),就会造成overfitting,即模型的variance会增大(想象一下摇晃半满的容器,里面水的形状是不稳定的)。
但是可以通过合理的训练方法获取更多的知识。
知识蒸馏使用的是Teacher—Student模型,其中teacher是“知识”的输出者,student是“知识”的接受者。知识蒸馏的过程分为2个阶段:
- 原始模型训练: 训练”Teacher模型”, 简称为Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。我们对”Teacher模型”不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入X, 其都能输出Y,其中Y经过softmax的映射,输出值对应相应类别的概率值。
- 精简模型训练: 训练”Student模型”, 简称为Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入X,其都能输出Y,Y经过softmax映射后同样能输出对应相应类别的概率值。
关键点
机器学习最根本的目的在于训练出在某个问题上泛化能力强的模型。
泛化能力强: 在某问题的所有数据上都能很好地反应输入和输出之间的关系,无论是训练数据,还是测试数据,还是任何属于该问题的未知数据。
负标签也包含了信息,和网络的泛化性能有关
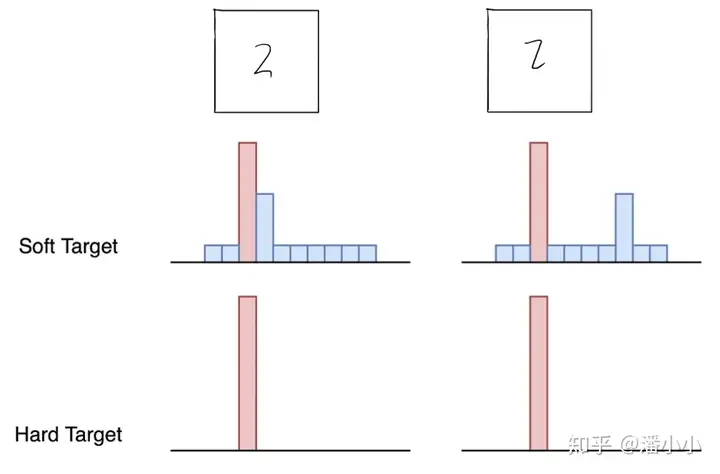
温度的高低改变的是Net-S训练过程中对负标签的关注程度: 温度较低时,对负标签的关注,尤其是那些显著低于平均值的负标签的关注较少;而温度较高时,负标签相关的值会相对增大,Net-S会相对多地关注到负标签。
矛盾点在于
从有部分信息量的负标签中学习 –> 温度要高一些
防止受负标签中噪声的影响 –>温度要低一些
训练
第一步是训练Net-T;第二步是在高温T下,蒸馏Net-T的知识到Net-S;推理过程使用T=1.
剪枝
- 删除不重要的权重,比如y=x+2*x^2 ,可以去除x的权重
- 深度学习模型中一般存在大量的冗余参数,模型剪枝即删除不重要的权重,可以缩减模型大小,提高模型计算效率。剪枝算法可以分为以下三个步骤:训练模型、模型剪枝、重新训练,并迭代以上三个步骤,直到模型精度达到目标。根据剪枝颗粒的不同,模型剪枝方法可以分为细粒度剪枝、向量剪枝、卷积核剪枝、滤波器剪枝。
神经网络水印
证明网络权重的产权问题
分类
- 基于内在机制的白盒神经网络水印
- 基于触发集的黑盒神经网络水印
- 基于输出结果的无盒神经网络水印
白盒(待修
修改网络权重,加入一个符合正态分布的全连接层,在这个全连接层中加入秘密信息(不明)
黑盒(待修
基于触发集,对于特定一系列图像有特定的输出,有点像对抗样本
- 问题在于只能在分类任务中使用
无盒
Watermarking Neural Networks with Watermarked Images
DOI 10.1109/TCSVT.2020.3030671
复日大学
Hanzhou Wu, Member, IEEE, Gen Liu, Yuwei Yao and Xinpeng Zhang
基于输出图像,效果和“完成输出之后,将图像输入一个带密钥的水印网络相似”
区别在于
| 无盒水印 | 后加水印 |
|---|---|
| 遗失的权重还具有水印 | 遗失无效 |

感觉这个鲁棒性的问题很大,可能噪声鲁棒性是网络训练完就自带的,但是剪切的鲁棒性没有加入noise layer不大可能有。
模型所有权技术
Fingerprint:hash/md5
模型相似度:Copy, Right? A Testing Framework for Copyright
Protection of Deep Learning Models
可逆神经网络INN-watermark
Invertible Neural Networks, INN
图像质量指标:PSNR(dB),SSIM ,MAE,RMSE
HiNet: Deep Image Hiding by Invertible Network
beihang unversity
github:https://github.com/TomTomTommi/HiNet
数据集:ImageNet, COCO and DIV2K datasets.
可逆神经网络,编解码部分使用相同的参数,可以减少模型大小
水印问题,编解码可以视为可逆问题。



DWT,IWT
离散小波变换,具有可逆性,逆小波变换。制造原始图像的高频分量,隐写域在图像的高频分量中。
1 | class DWT(nn.Module): |
INN代码实现
主网络
主要特点为编解码可逆
1 | def forward(self, x, rev=False): |
INV_block
φ ρ η网络是相同的残差块,参数不共享
在解码网络中,直接设置rev=true
1 | class INV_block(nn.Module): |

error: subprocess-exited-with-error错误解决方案,即pip 安装第三方包问题
有些说是pip版本不对
实际上,安装不上包的原因有很多,这次是因为内存不足,无法安装造成的报错,删除一些不用的包或者不用的大文件即可
安装torch脚本(重要)
注意不要漏打
python 版本 应该高点,3.10左右吧,pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 –extra-index-url https://download.pytorch.org/whl/cu116
python==3.8,pip install torch==1.8.1+cu101 torchvision==0.9.1+cu101 –extra-index-url https://download.pytorch.org/whl/cu101
https://download.pytorch.org/whl/cu117详见
生成requirements.txt
pip install pipreqs
pipreqs .
或限定编码方式为utf8,否则会有编码错误error
pipreqs ./ –encoding=utf8
A Survey of Large Language Models
三步:pre-training ,adaptation tuning,design suitable prompting strategies
即:预训练,调优,和提示策略
调优
RLHF系统主要由三个关键部分组成:预先训练好的LM,从人类反馈中学习的奖励模型,以及训练LM的RL算法(RL强化学习)
提示策略
- in-context learning
ICL:上下文学习in-context learning
ICL用一个自然语言描述、几个演示程序和一个测试查询来提示llm。
CoT
- Chain-of-Thought Prompting(CoT)
CoT提示则涉及到提示中的一系列中间推理步骤。
推理步骤:
If a rectangle has a length of 6 cm and a width of 3 cm,
what is the perimeter of the rectangle?
For a rectangle, add up the length and width and double it.
So, the perimeter of this rectangle is (6 + 3) x 2 = 18 cm.
改进CoT
- Few-shot CoT.
Enhanced CoT strategies
自一致性策略
作为改进的CoT策略,生成多个推理路径,所有推理结果获得一个集合,投票决定
- Zero-shot CoT.
零镜头CoT在提示中不包含人工注释的任务演示。相反,它直接生成推理步骤,然后使用生成的cot来推导答案。
模型专门化
In addition to directly utilizing LLMs with ICL and CoT, some recent studies explore how to specialize the ability of LLMs towards specifific tasks [255–257], which is called model specialization [258]. For example, the researchers in [258] specialize the ability of mathematical reasoning from LLMs through fifine-tuning the small-scale Flan-T5 [81] on CoT reasoning paths generated by LLMs. Model specialization can also be applied to solve a variety of tasks like question answering [259], code synthesis [260], and information retrieval [261].
模型专门化是本次任务的重点,相对于一种通用的LLM模型,应当获取一个应用于特定领域的语音模型
现有语音模型任务
现有的语言生成任务大致可以分为语言建模任务、条件文本生成任务和代码合成任务。
LLM使用知识 Knowledge Utilization
Closed-Book QA
闭卷问答
只能使用train前用于训练的基础知识,如自然问题[283]、Web问题[286]和TriviaQA [287]
只能根据上下文回答
open-Book QA
开卷问答
回答过程是可以联网的
open-book QA数据集(例如,自然问题[283]、OpenBookQA [295]和SQuAD [298])与封闭书QA数据集有重叠,但它们包含了外部数据源,例如,维基百科
Knowledge Completion.
问题: Hallucination (幻觉产生)
就是LLM模型骗人,胡乱生成回答内容。在所有的LLM模型中都存在
本质上讲,llm似乎是“无意识地”利用知识来解决任务,而这仍然缺乏准确控制内在或外部知识使用的能力
评估幻觉问题,人们提出了一组幻觉检测任务,如真实QA[285],用于检测被模型模拟的人类谎言
问题:Knowledge recency(知识更新)
新的知识和重新训练过程中的灾难性遗忘问题
通过外接搜索引擎可以缓解这个问题
复杂推理
复杂推理是指理解和利用支持证据或逻辑得出结论或做出决策的能力。根据推理过程中所涉及的逻辑和证据的类型,我们考虑将现有的评价任务分为知识推理、符号推理和数学推理三类
知识推理
LLMs may have diffificulty in explicitly inferring the commonsense knowledge required by a specifific task, though they can successfully solve it.




