easy misc 1
原创
: [安洵杯 2019]easy misc 1
[安洵杯 2019]easy misc 1


拿到一个压缩包
里面有一个加密的压缩包

这个压缩包里面有一个神秘的 代码,先把数值计算出来吧。反正misc的题目总是这个样子,也不是第一天知道了。
那么就先计算一个这个数值吧,
1 | import math |
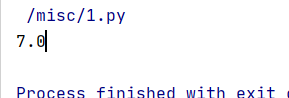
算出来是7呀
FLAG IN ((√2524921X85÷5+2)÷15-1794)+NNULLULL,
这个东西理解起来铁定是有二义性的呀。
7+NNULLULL,
7NNULLULL,
都不对
发现这个原来是掩膜爆破
a = dIW
b = sSD
c = adE
d = jVf
e = QW8
f = SA=
g = jBt
h = 5RE
i = tRQ
j = SPA
k = 8DS
l = XiE
m = S8S
n = MkF
o = T9p
p = PS5
q = E/S
r = -sd
s = SQW
t = obW
u = /WS
v = SD9
w = cw=
x = ASD
y = FTa
z = AE7
这个格式有点熟悉,显示替换密码的形式
但是现在就是知道这些
也没有用,因为这也不可能把这个一篇哈利波特全部給替换掉的吧。
 知道替换密码的形式,也知道了密文是哈利波特与魔法石??。
知道替换密码的形式,也知道了密文是哈利波特与魔法石??。
那么这张图片可能有别的 用处了。

图片png 分析,什么pngcheck,stegsolve的来一波。
没什么用
用binwalk 测试
没有分离出来有用 的信息
有一件事情想不通,就是在winhex中搜索IDATx,x后面并没有789C. 这个应该是ZLIB的标识才是。 那么岂不是有问题。

使用foremost命令分离,发现输出了两张图片。
亦或?还是直接stegsolve?
盲水印
不是很懂这个东西
所以说图像这个二维的信息还是很复杂的。


虽然是知道它隐写的行为,但是分不清隐写的类型。
而且一般情况下,在互联网环境下,藏在一系列的图像中,我们甚至是不知道隐写的行为。
1 | from blind_watermark import WaterMark |
出事了,解不出来。
在艰难的斗争之后,我发现了盲点。
命令如下
1 | python bwmforpy3.py decode 00000000.png 00000232.png 1.png --oldseed |
这个作者就是神
python 3.6
盲水印脚本安装说明

依稀可以看出来这个是
in 11.txt

这个哈利波特文章还挺长的。
明显就是字频分析,可能还得先做一个替换在来字频分析。

1 | a = dIW |
大概有40万个字,要是先替换再字频分析,替换完成之后大概翻3倍。 这个字频分析的脚本无论是抄还是写都不是很难的事情。
记得以前抄过一个代码
1 | #!/usr/bin/env python |
Python 3.7.0 (default, Jun 28 2018, 08:04:48) [MSC v.1912 64 bit (AMD64)]
Type ‘copyright’, ‘credits’ or ‘license’ for more information
IPython 6.5.0 – An enhanced Interactive Python. Type ‘?’ for help.
PyDev console: using IPython 6.5.0
Python 3.7.0 (default, Jun 28 2018, 08:04:48) [MSC v.1912 64 bit (AMD64)] on win32
In[2]: runfile(‘C:/Users/brighten/Desktop/信息安全工具快捷/misc/字频分析.py’, wdir=‘C:/Users/brighten/Desktop/信息安全工具快捷/misc’)
items:
dict_items([(‘a’, 25887), (‘b’, 4980), (‘c’, 6403), (‘d’, 15932), (‘e’, 39628), (‘f’, 6431), (‘g’, 8127), (‘h’, 19535), (‘i’, 19422), (‘j’, 319), (‘k’, 3930), (‘l’, 14385), (‘m’, 6729), (‘n’, 21337), (‘o’, 25809), (‘p’, 4909), (‘q’, 217), (‘r’, 20990), (‘s’, 18870), (‘t’, 27993), (‘u’, 9562), (‘v’, 2716), (‘w’, 7744), (‘x’, 381), (‘y’, 8293), (‘z’, 259), (‘A’, 703), (‘B’, 348), (‘C’, 293), (‘D’, 685), (‘E’, 287), (‘F’, 426), (‘G’, 492), (‘H’, 2996), (‘I’, 1393), (‘J’, 51), (‘K’, 79), (‘L’, 209), (‘M’, 665), (‘N’, 488), (‘O’, 332), (‘P’, 639), (‘Q’, 203), (‘R’, 660), (‘S’, 844), (‘T’, 1055), (‘U’, 193), (‘V’, 192), (‘W’, 653), (‘X’, 2), (‘Y’, 326), (‘Z’, 5), (‘1’, 11), (‘2’, 3), (‘3’, 8), (‘4’, 6), (‘5’, 2), (‘6’, 1), (‘7’, 4), (‘8’, 1), (‘9’, 4), (‘0’, 5), (’!’, 474), (’@’, 0), (’#’, 0), (’KaTeX parse error: Double superscript at position 171: … (’]’, 0)]) [’ ‘̲, ’e’, ‘t’, ‘a’…’, ‘#’]
etaonrhisdluygwmfcbpkHv-ITSADMRWPGN!FxBOYjCEzqLQUVKJ)(134Z0972X5*86}{_^][@=+&%$#
[’ ’, ‘e’, ‘t’, ‘a’, ‘o’, ‘n’, ‘r’, ‘h’, ‘i’, ‘s’, ‘d’, ‘l’, ‘u’, ‘y’, ‘g’, ‘w’, ‘m’, ‘f’, ‘c’, ‘b’, ‘p’, ‘k’, ‘H’, ‘v’, ‘-’, ‘I’, ‘T’, ‘S’, ‘A’, ‘D’, ‘M’, ‘R’, ‘W’, ‘P’, ‘G’, ‘N’, ‘!’, ‘F’, ‘x’, ‘B’, ‘O’, ‘Y’, ‘j’, ‘C’, ‘E’, ‘z’, ‘q’, ‘L’, ‘Q’, ‘U’, ‘V’, ‘K’, ‘J’, ‘)’, ‘(’, ‘1’, ‘3’, ‘4’, ‘Z’, ‘0’, ‘9’, ‘7’, ‘2’, ‘X’, ‘5’, ‘*’, ‘8’, ‘6’, ‘}’, ‘{’, ‘_’, ‘^’, ‘]’, ‘[’, ‘@’, ‘=’, ‘+’, ‘&’, ‘%’, ‘$’, ‘#’]
排序为 etaonrhisdluygwmfcbpkHv-ITSADMRWPGN!FxBOYjCEzqLQUVKJ)(134Z0972X5*86}{_^][@=+&%$#
1 | a = dIW |
etaonrhisdluygwmf
1 | #!/usr/bin/env python |
In[2]: runfile(‘C:/Users/brighten/Desktop/信息安全工具快捷/misc/字符替换脚本.py’,
wdir=‘C:/Users/brighten/Desktop/信息安全工具快捷/misc’) {‘a’: ‘dIW’, ‘b’:
‘sSD’, ‘c’: ‘adE’, ‘d’: ‘jVf’, ‘e’: ‘QW8’, ‘f’: ‘SA=’, ‘g’: ‘jBt’,
‘h’: ‘5RE’, ‘i’: ‘tRQ’, ‘j’: ‘SPA’, ‘k’: ‘8DS’, ‘l’: ‘XiE’, ‘m’:
‘S8S’, ‘n’: ‘MkF’, ‘o’: ‘T9p’, ‘p’: ‘PS5’, ‘q’: ‘E/S’, ‘r’: ‘-sd’,
‘s’: ‘SQW’, ‘t’: ‘obW’, ‘u’: ‘/WS’, ‘v’: ‘SD9’, ‘w’: ‘cw=’, ‘x’:
‘ASD’, ‘y’: ‘FTa’, ‘z’: ‘AE7’}
QW8obWdIWT9pMkF-sd5REtRQSQWjVfXiE/WSFTajBtcw=
QW8obWdIWT9pMkF-sd5REtRQSQWjVfXiE/WSFTajBtcw=
这个明显就是base系列的,看别人的题解,说是这个编码有问题。
再做下去没有意义了。本题就到这里结束。



