ManTra-Net- Manipulation Tracing Network For Detection And Localization of Image Forgeries With Anom
原创
: ManTra-Net: Manipulation Tracing Network For Detection And Localization of Image Forgeries With Anom
ManTra-Net: Manipulation Tracing Network For Detection And Localization of Image Forgeries With Anom
篡改检测问题可以看作是特殊的语义分割问题 是一个局部异常检测问题。
重点
主要贡献
(1)ZPool2D
DNN层,以Z-score方式标准化了局部特征与其参考之间的差异;
(2)从远到近的分析,该分析对从不同分辨率汇集的ZPool2D特征图执行Conv2DLSTM顺序分析。
ZPool2D计算
区域的主要特征定义为所有像素的平均。
主要特征和其他特征的差异为DF,是像素的数值-主要特征的数值。
ZF为DF的标准化。

像素级的分类。输出每个像素的pred篡改类型,总计为385个小类别。
385个小类别是由篡改类型分类 7分类 细化分类。
压缩、模糊、形态学、对比度操作、附加噪声、重采样和量化


那么这个4个重复的ZPOOL2D是什么意图呢。
是为了解决在图像中存在多个篡改区域的问题,
根据各个篡改块之间的相对关系,主要特征UF可能不是原有的图像代表的这个特征UB。
而变为了篡改区域的特诊UR2。此时,网络无法检测出UR2的篡改区域。
当存在多个篡改区域时,图像的主要特征UF更接近UR2的情况。

这个情况下,分割图像块,分别进行预测,就可以缓解这个问题,但是仍然会有问题,可能预测错误的面积会变得更小。
而且分为小块的块的大小很难确定。
解决方案:使用不同大小的batch 分割图像,并对每个分割块分别进行预测。将预测结果按序输入LSTM,由LSTM提取每个batch的关系。
原因在于篡改块是由空间局部性联系的。
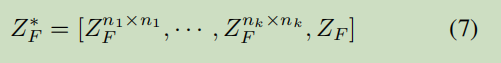
经过 ZPool2D计算,获得的是多个的batch 块。
Timeconcat结构
1 | input_lstm = torch.cat( |
将所有的Zpooling 堆叠。作为LSTM的input。
Conv2DLSTM
人类感知的实质是远近分析,当人看不清时,往往会近些看。
LSTM从远到近的分析
是一个普通的LSTM 结构
对于大的篡改区域
算法设计的核心认为以batch 内的主要特征为主,与这个主要特征完全不一致的认为是篡改的像素,并像素级的分类为不同的篡改类型。
认定篡改区域小于全像素的一半
那么,对于这个算法,认定篡改区域小于全像素的一半就极其的重要了。
若篡改区域大于50% ,则有很大可能,网络认为篡改区域是主要的区域,那么。
那么在特定的异常样本中,gt的标注和理论上应当预测的结果就会完全的相反。这对于网络的训练是极其的不利的。
因此,作者规定:若篡改区域大于50%,则 对于权重变化无影响。

篡改区域大小与分类二义性
这篇文章认定篡改块必然是图像中面积占比较小的一块。




