TERA- Screen-to-Camera Image Code with Transparency, Efficiency, Robustness and Adaptability论文阅读
原创
: TERA: Screen-to-Camera Image Code with Transparency, Efficiency, Robustness and Adaptability论文阅读
TERA: Screen-to-Camera Image Code with Transparency, Efficiency, Robustness and Adaptability论文阅读
作者单位中科院
文章仅供自学
研究主题
可以应对
Screen-to-Camera的水印,且满足四个要求:高透明度,高嵌入效率,传输鲁棒性强,对设备类型的适应性强
这四个指标作为重点。这篇文章的主要归类为时域水印,高透明度水印。
核心思路
人眼视觉和机器视觉存在偏差,主要在于人眼的视觉残留现象,会将screen中刷新率大于60Hz的连续图像进行融合。
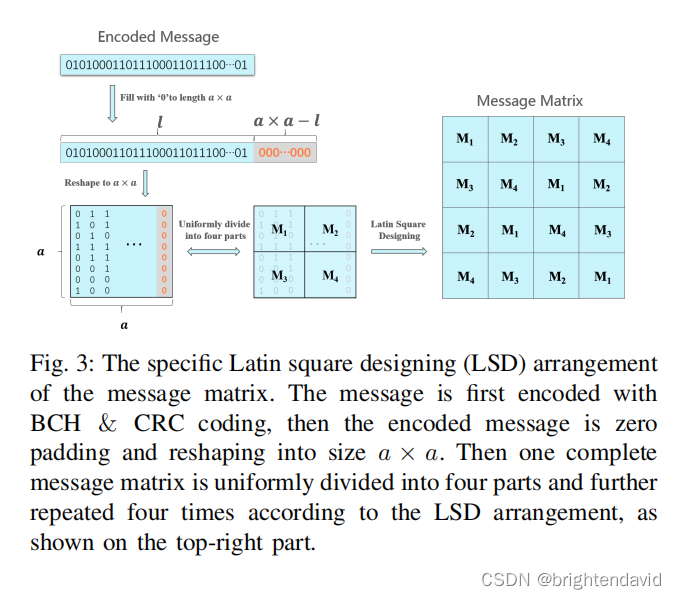
消息编码法
消息编码实际上没有一个定论,说哪一种表现形式更好。重复编码块,实现鲁棒性,防止消息受到不可复原的破坏。就是l长度的消息+CRC校验码,最后补0到a*a长度。只要最终的消息M1,M2,M3,M4完整,即可完成提取。理论上可以损失3/4的消息。
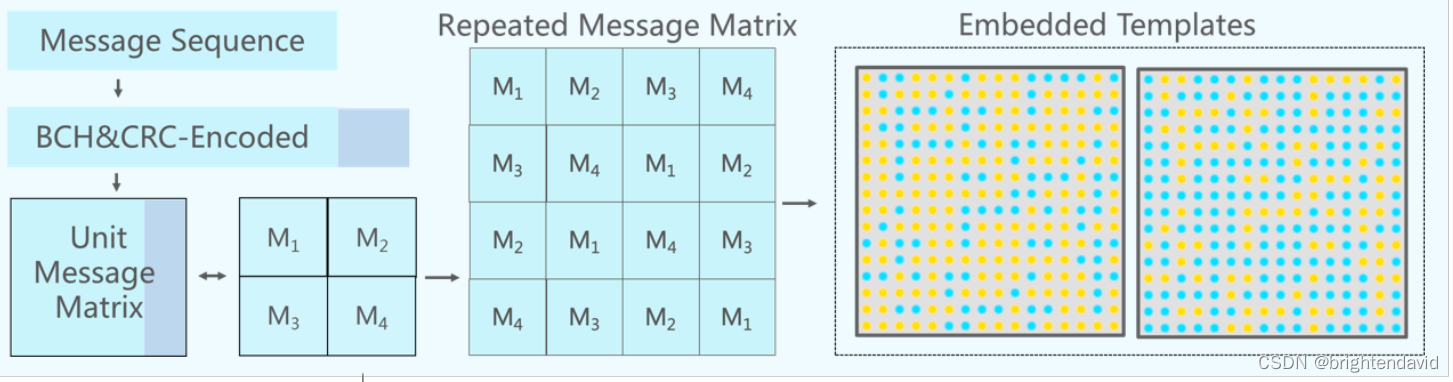
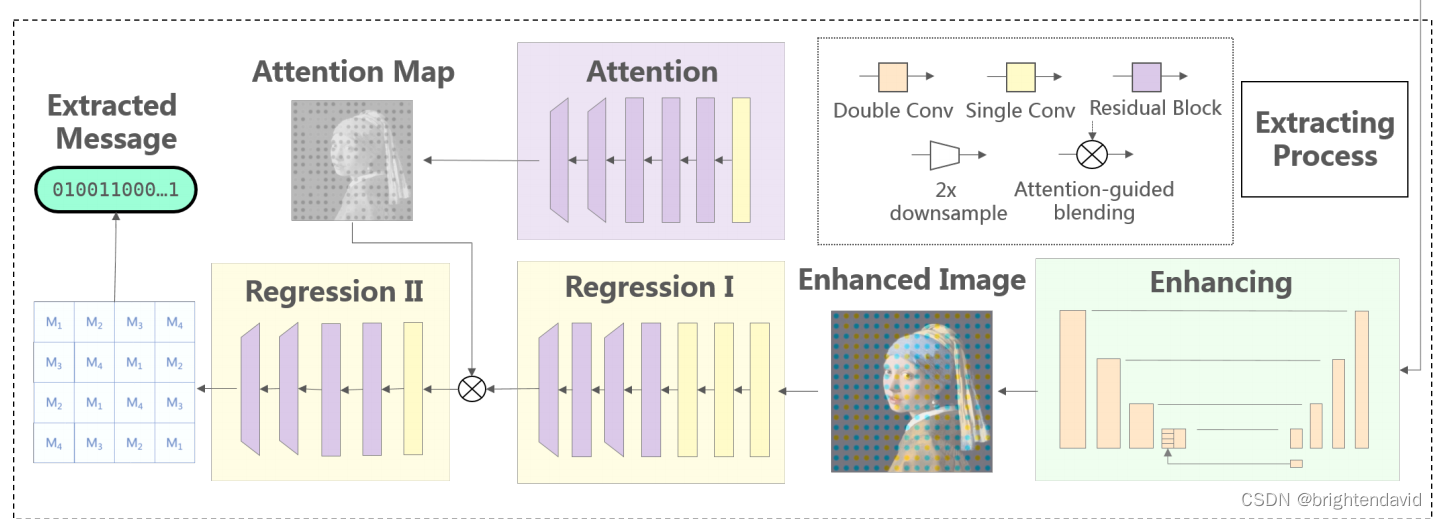
嵌入模块
根据应用场景,使用图像处理分解为I+和I-两个图像进行编码,再通过注意力引导网络进行解码,本质上属于高透明度的水印方法,和原图进行加权相加方式加入水印


嵌入公式如下,其本质在于公式5,这是一个透明度水印;而其核心思路(人眼的融合策略)体现在公式3,加权和显然是原图

上面的几个公式就说明了以下事实:
扰动模块
文章里面说是那照相机捕获相机中的图像,我觉得不大行,主要是贵。
文章中也提到
2019年这篇文章实现了screen-camera的模拟,这种模拟至少在那篇论文中是可行的,但是Strgstamp这篇论文的screen-camera步骤感觉奇奇怪怪的,特别是detect步骤。
stegstamp(cvpr 2019):模仿了照相机-屏幕的转换
提取模块
提取方式为3阶段网络:强化-注意力-回归子网,施加不同loss;以及对抗子网对强化网络的图像质量进行约束(patch-gan)进行判别。
这个提取模块还挺复杂的。主要是通过增强和注意力机制来缓解screen-camera的信息损失。Loss就不写了。