Visual Agentic AI
Visual Agentic AI for Spatial Reasoning with a Dynamic API
视觉代理AI用于空间推理和动态api
作者:加州理工学院
代码:https://glab-caltech.github.io/vadar/
来源:cvpr2025
用途:用于视觉推理(解读视觉世界),在三维空间推理中回答问题。
经典的VLM(视觉语言模型)主要擅长于类别级别的语义理解。当被要求在三维世界中进行空间理解时,它们的性能显著下降。
在回答三维世界中问题,例如已知桌子高20米,那么图中镜子的半径是多少?

就需要定位相关对象,确定尺寸,计算三维大小。GPT-4给出了错误答案。
- 现有方法往往依赖静态的人为定义的api解决问题。
- 仅进行一次静态图像扫描,无法主动探索细节
- 视觉信息被压缩为静态上下文,丢失时空动态性
- 难以有效整合几何结构信息,导致空间逻辑混乱
创新
提出了一种代理程序合成方法,其中大语言模型代理协同生成一个具有新函数的Pythonic API,以解决常见的子问题。 我们的方法克服了以往依赖静态、人工定义API方法的局限,能够处理更广泛的查询。将这个方法称为VADAR。
- 多agent协作
- 由大语言模型生成的动态api,而不是以往的固定静态的人工定义的API
- 具有一定可解释性
核心
由大模型生成动态API,可以拓展一应对新的查询。
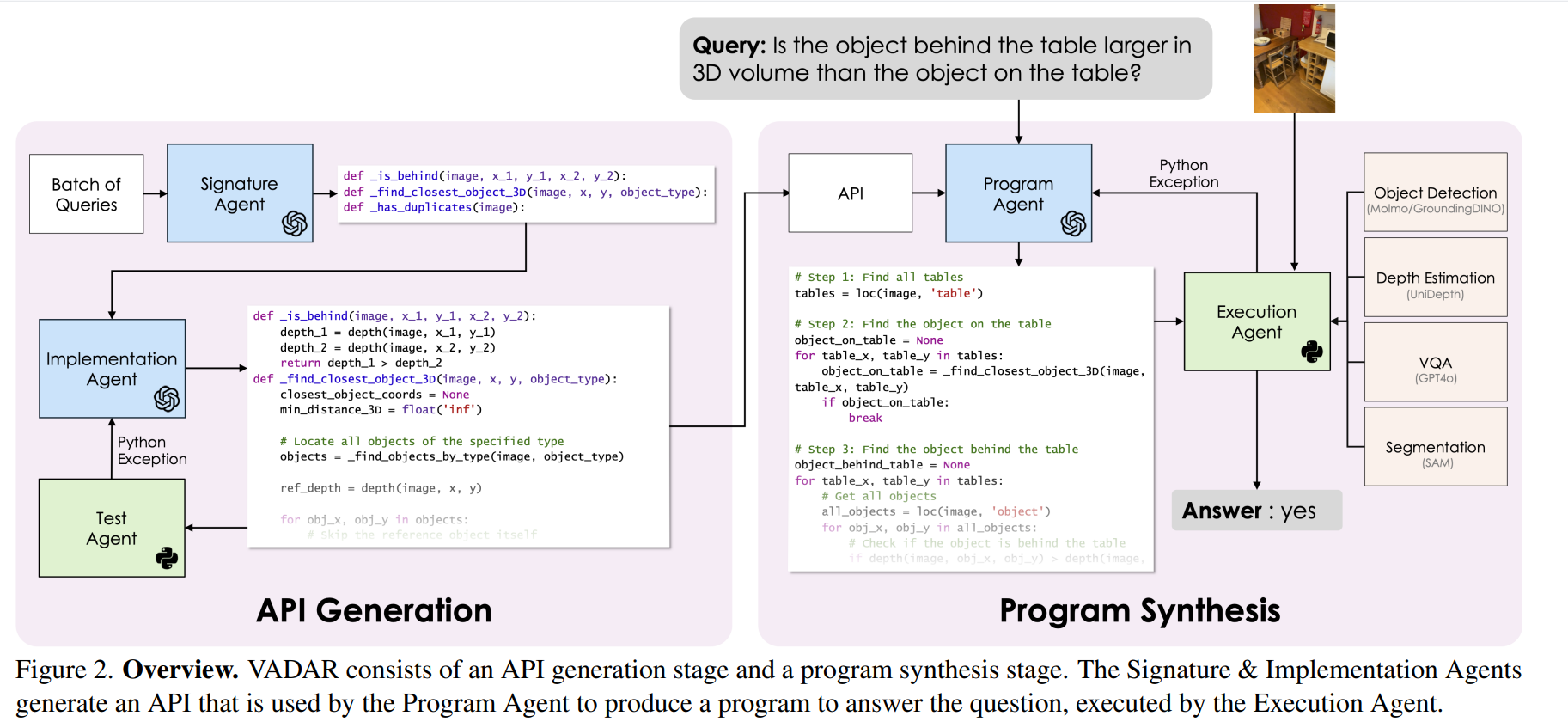
- 一部分的api通过调用现有的大模型生成,例如:用Moimo进行目标识别,UniDepth的深度估计模块,GPT-4o的VGA视觉问答模块,SAM的语义分割模块。这一部分是通用的一些功能,完成3D环境下的视觉问答必然需要解决这些问题。如右侧所示。
- 另一部分,就是解决这个问题的程序化流程api需要动态生成。这一部分是通过大模型生成的。
Signature Agent
- 含义:签名代理,这里的“Signature”指的是 Agent 动态生成的工具接口定义。Agent 不仅仅是“调用”工具,而是“创造”了工具及其签名。
- 相当于定义了函数名,输入输出结构。
接受N个Queries(N=15),针对这些问题可能产出的子问题生成通用的方法签名。
Agent接受当前API状态作为文档字符串 ,不需要上下文示例(with out in-context examples),能够生成更加多样性的api,具有更广泛的功能潜力(wider potential functionality)。
Implemention Agent
- 含义:实现代理
- 就是实现由signature Agent定义的函数细节
需要上下文示例,因为这部分的实现需要注重准确性,而不是多样性。就是here are some examples of how to implement a method given its docstring and signature.
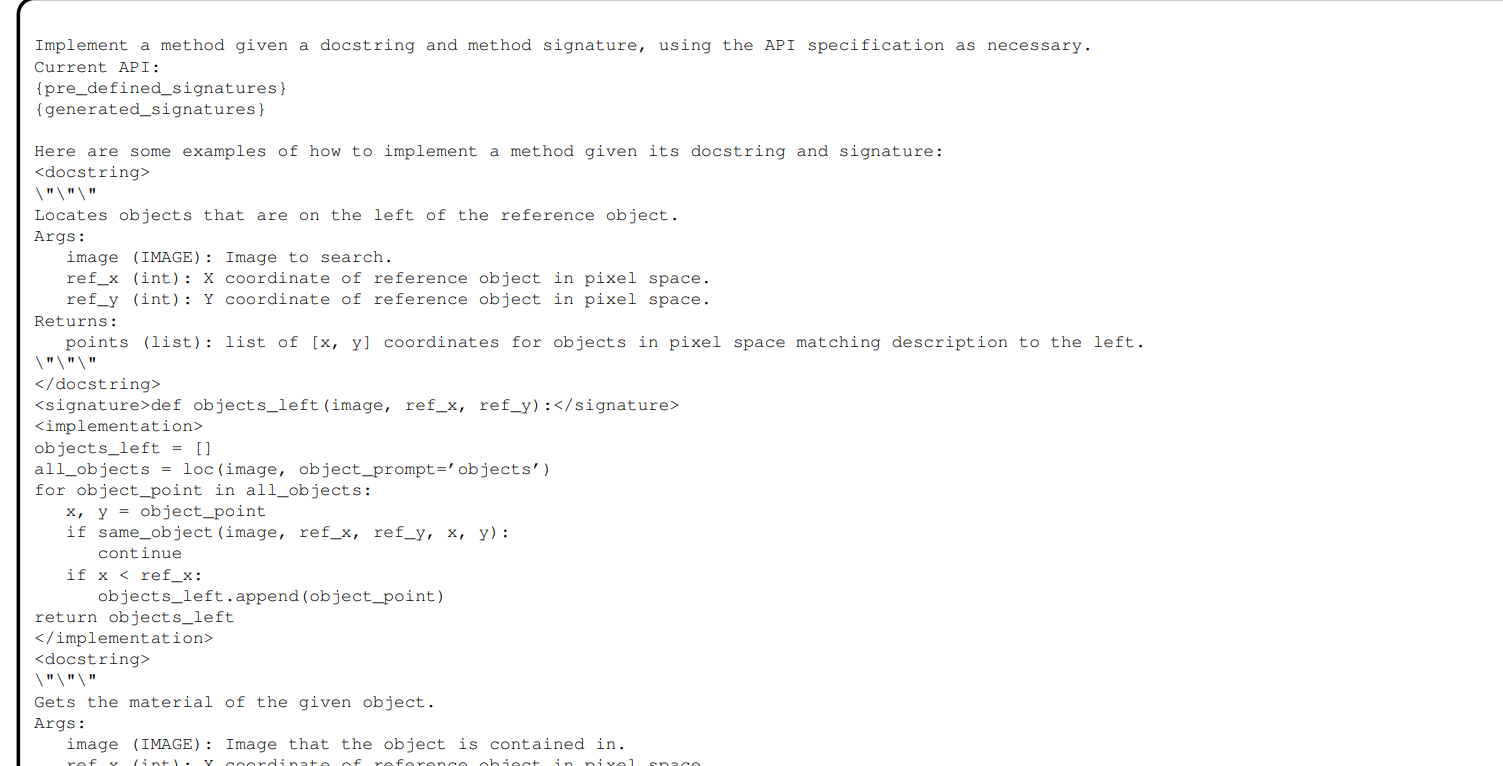
test agent
深度优先实现。一旦方法根据签名实现完成,test agent通过使用占位符输入运行该方法。如果发生错误,test agent向Implemention Agent发送异常Exception.如果包含未实现方法,测试无法进行,在这种情况,会遍历一个隐式的依赖图。
Program agent(总agent)
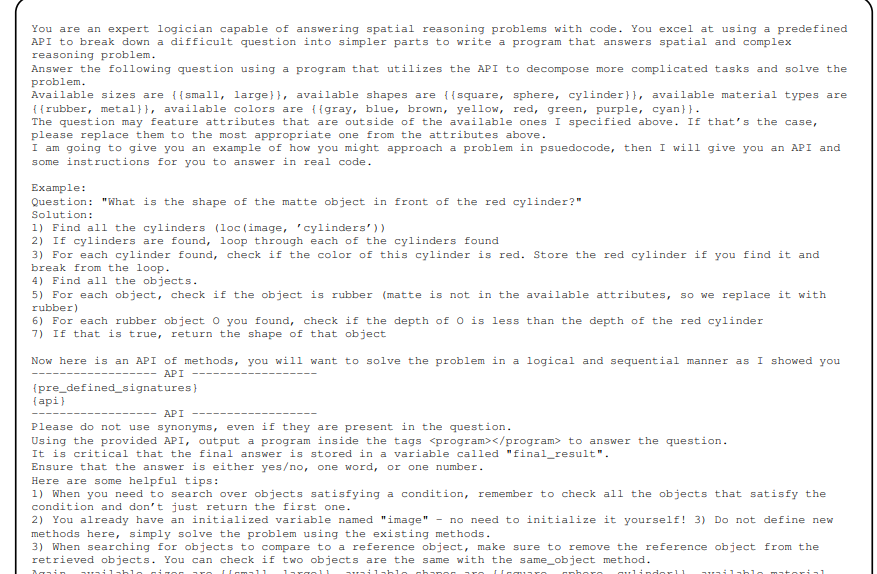
这一部分模型只是写了一段提示词而已。试验了两种模型:CLEVR和OMNI3D-BENCH。



