MedCLIPSeg
MedCLIPSeg: Probabilistic Vision-Language Adaptation for Data-Efficient and Generalizable Medical Image Segmentation
med clip seg:医学图像分割,基于概率的视觉语言适应用于高效通用的医学图像分割
Paper: https://arxiv.org/abs/2602.20423
Code: https://github.com/HealthX-Lab/MedCLIPSeg
Project: https://tahakoleilat.github.io/MedCLIPSeg
来源:cvpr 2026
模型/数据:huggingface.co/TahaKoleilat/MedCLIPSeg
作者:康科迪亚大学-加拿大
主要缝合:CLIP, MaPLe, and LViT ,所以说缝合3篇A+B+C缝合的好就可以发顶刊。
- 其中,CLIP是基础模型
- MaPLe是中间的融合法,如何将图像特征和文本特征进行融合,以及信息交互,相互查询。
- LViT是以下公式,以及基本的输入输出结构就是图像描述+CT图像。
Pt = βPt − 1 + (1 − β)Pt, β = 0.99
🧠 Model Overview
Backbone: UniMedCLIP ViT-B/16
Task: Medical Image Segmentation
Modalities: Ultrasound, MRI, Endoscopy, Dermoscopy, X-ray
- Training Regimes
- Data Efficiency Evaluation
- Fully supervised learning
- Domain generalization
我感觉这一工作做得还行,可以作为借鉴。用于少样本、半监督模式的一个范式
目的
医学图像分割(medical image segmentation)仍因标注数据优先,解剖特征模糊以及领域偏移等问题具有挑战性。尽管视觉-语言模型如CLIP提供了强大的跨模态表示,其在密集,文本引导的医学图像分割的潜力仍旧被忽视(remain under explored)。一部分是未标注的数据(90%),一部分是有像素级标注的数据(10%)。可以看做是一种半监督学习。
| 维度 | 有标注数据 (Pixel Masks) | 无标注/文本数据 (Text/Reports) |
|---|---|---|
| 数据形式 | 精确的像素级分割图 (Mask) | 自然语言描述 (如 “不规则肿块”) |
| 获取成本 | 极高 (需专家逐像素勾画) | 低 (医生写报告即生成) |
| 在模型中的角色 | 校准器:用于训练 Adapter,修正分割边界 | 引导者:提供语义搜索目标,定位病灶区域 |
| 训练方式 | 有监督学习:计算 Dice/BCE 损失 | 自监督/对比学习:利用冻结的 CLIP 计算图文相似度 |
| 处理机制 | 学习空间分布 (在哪里分割) | 学习语义对齐 (这是什么东西) |
| 依赖程度 | 极低 (仅需 10% 即可达到 SOTA) | 极高 (依赖 CLIP 的预训练知识) |
| 特性 | 典型半监督学习 (Semi-Supervised) | MedCLIPSeg (Vision-Language) |
|---|---|---|
| 核心资源 | 无标签图像 + 少量标注图像 | 文本描述 + 少量标注图像 |
| 监督信号 | 图像本身的几何/统计一致性 | 文本语义(Text Prompt) |
| 标注成本 | 节省了标注时间(因为不用标) | 节省了标注时间(因为用文字代替画框) |
| 主要技术 | 伪标签、一致性正则化 | 概率化注意力、软对比损失、图文对齐 |
| 解决痛点 | 数据量少 | 域偏移、边界模糊、标注昂贵 |
背景
准确的医学分割是依赖诊断,治疗计划和定量临床随访的基石。有三个方面的障碍和限制:
- 分割GT的标注成本,标注的不一致性
- 病灶和器官可能展示模糊的边界,由于强度过渡或者部分体积效应。
- 扫描设备、采集协议和患者个体差异,扫描中常见的领域转移,导致仅基于分布内的数据训练得到的模型面对分布外的数据时失效。
迫切需要一种同时具备数据高效性、不确定性敏感、跨领域泛化能力的分割模型。
在医学分割领域,以往可以通过以下方法实现:
- U-Net等CNN模型
- ViT架构
这些模型依赖大量的像素级监督,大多数模型运行时确定性的(deterministically).在处理分布外的输入和边界模糊的样本时,存在系统性的过度自信(systematically over-confident),在缺乏预警机制的情况下,产生不可靠的分割结果。
在传统的确定性特征学习方法的问题下,未能充分考虑模糊性和特征之间的局部不一致。
Learning methods that can adaptively weigh evidence and/or modulate attention based on contextual reliability of data distribution would be hopeful to address this [53].
能够根据数据分布的上下文可靠性自适应权衡证据,或者
调节注意力
的学习方法有望解决这个问题[53]。
[53] Alireza Mehrtash, William M Wells, Clare M Tempany, Purang Abolmaesumi, and Tina Kapur. Confidence calibration and predictive uncertainty estimation for deep medical image segmentation. IEEE transactions on medical imaging, 39(12):3868–3878, 2020. 2
这两个方法可以解决这个问题。
主要创新
- Bidirectional Vision–Language Fusion: Introduce representation-level fusion modules that enable efficient bidirectional interaction between image and text features while keeping CLIP encoders frozen, improving data efficiency and robustness.双向视觉-语言融合:引入表征级融合模块,实现图像与文本特征之间的高效双向交互,同时保持CLIP编码器冻结状态,从而提升数据效率和鲁棒性。
- Probabilistic Cross-Modal Attention: Model vision–language attention using variational Key–Value formulations to capture uncertainty, leading to improved segmentation accuracy and cross-domain generalization.概率跨模态注意力:利用变分键值公式建模视觉与语言之间的注意力,以捕捉不确定性,从而提升分割精度并增强跨领域泛化能力。
- Pixel-Level Uncertainty Estimation: Generate dense uncertainty maps by sampling attention Values from learned probability distributions, providing intuitive reliability estimates for clinical interpretation.像素级不确定性估计:通过从学习到的概率分布中采样注意力值,生成密集的不确定性图,为临床解读提供直观的可靠性评估。
- Extensive Multi-Modal Segmentation Evaluation: Conduct comprehensive evaluation against state-of-the-art methods across 5 imaging modalities and 6 organs and 16 datasets, assessing data efficiency, domain generalization, and the contribution of individual model components.广泛的多模态分割评估:针对5种成像模态、6个器官和16个数据集,全面对比当前最先进方法,评估其数据效率、领域泛化能力以及各模型组件的贡献。
具体实施方法
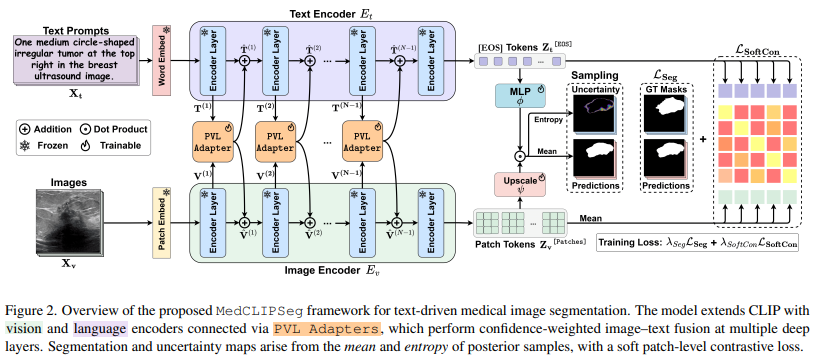
输入部分
- Xt为文本输入,就是分割的文本描述,就是任务描述“乳腺超声图像上右上方有一个中等大小的圆形不规则肿物。”意思就是医生很少做逐像素标注CT图的活,但是这类文本描述做得很多。
- Xv为图像输入就是CT图,待处理的图像。
模型
- 几乎是根据CLIP模型修改的。
- CLIP就是把文本-图像全部转换到高维特征,计算两个高维特征的相似度。
- 看到图中,把CLIP的文本编码器和图像编码器全部Frozen(with torch . no_grad),参数不可变,直接使用的预训练的权重,不参与参数变动。
- 可训练的参数只有PVL Adapter模块和后面的MLP
- PVL Adapter,训练新加入的轻量级 Adapter,这个模块非常重要。属于即插即用的,类Lora的设计思路。
PVL Adapter
分为三个小部分,可以看做一个U-net结构的残差块。
- 下采样部分
- 双向交互部分
- 上采样部分
这只是一个信息交互的模块,其实换成其他的东西也行。但是其中的Attn模块设计是比较重要的,这个模块中学习的是数据的分布,包括平均数和方差,而不是直接预测数据。
这一模块的源码如下:
1 | class PVL_Adapter(nn.Module): |
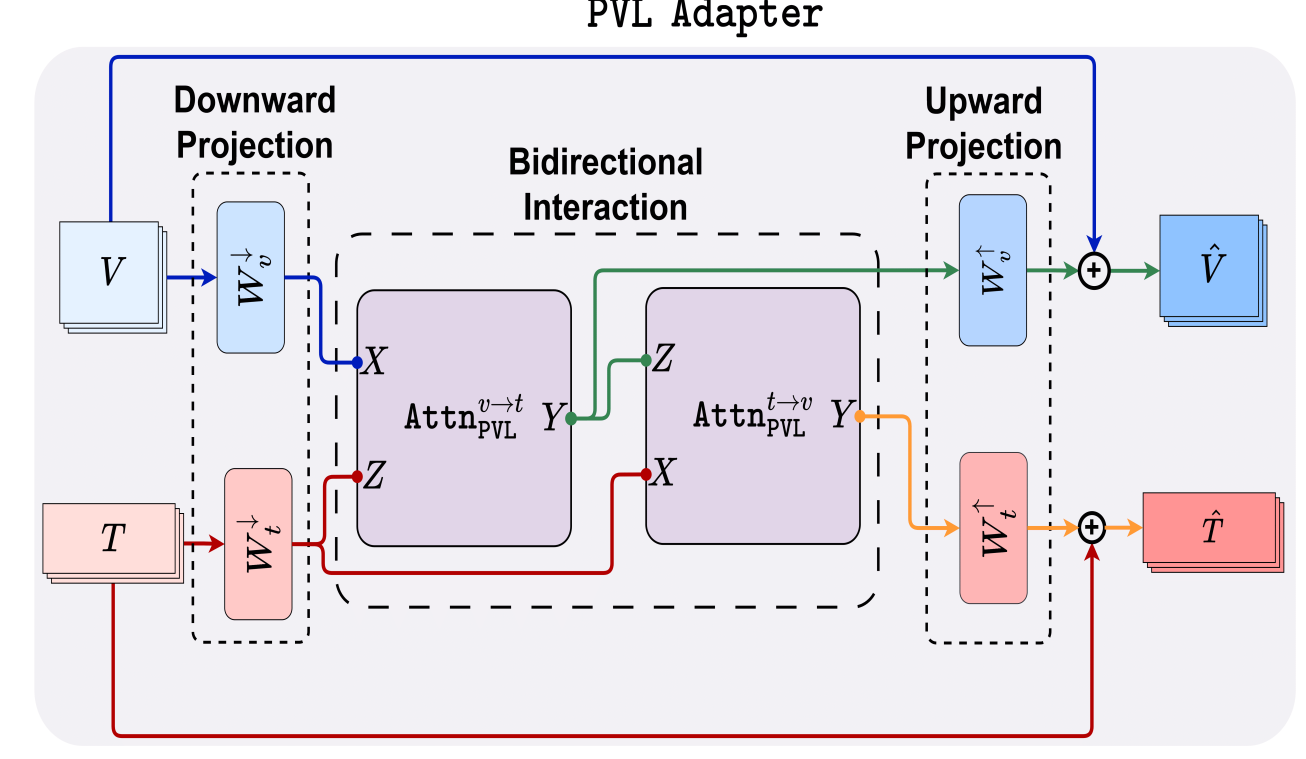 这一结构作为两种特征提取的连接部分,负责特征融合,学习不确定性的功能。
其实目标分割的任务用原本的CLIP预训练模型就能做,这一部分是这篇论文的核心创新点,让模型学习到不确定性,不确定性大的可以说“不知道”。
可以双向查询,即不仅可以文本T查询图像V,也可以图像V查询文本T。
这一结构作为两种特征提取的连接部分,负责特征融合,学习不确定性的功能。
其实目标分割的任务用原本的CLIP预训练模型就能做,这一部分是这篇论文的核心创新点,让模型学习到不确定性,不确定性大的可以说“不知道”。
可以双向查询,即不仅可以文本T查询图像V,也可以图像V查询文本T。
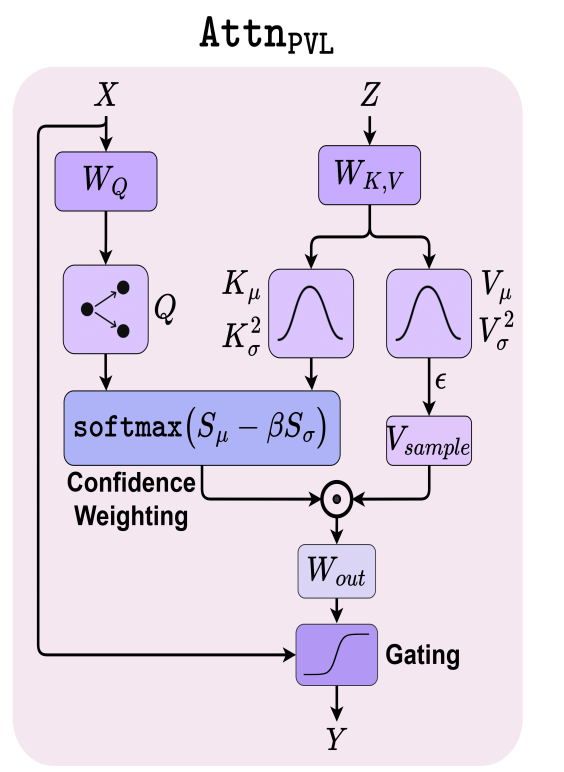 具体可见代码部分
只能说K,V的方差和均值都是硬拆的
只有Q的方差和均值是算出来的
方差可以看做是一个惩罚项,方差越大,置信度就越低,给的注意力权重就越低。
这个模型预估了一个分布,而不是一个点,所以模型可以学习到不确定性
具体可见代码部分
只能说K,V的方差和均值都是硬拆的
只有Q的方差和均值是算出来的
方差可以看做是一个惩罚项,方差越大,置信度就越低,给的注意力权重就越低。
这个模型预估了一个分布,而不是一个点,所以模型可以学习到不确定性
其中,Softplus激活函数的计算方法如下,这个函数在torch.nn模块中有实现 $$ \text{Softplus}(x) = \frac{1}{\beta} * \log(1 + \exp(\beta * x)) $$
Attn_PVL模块
1 | class TwoWayTransformerLayer(nn.Module): |
1 | class ProbCrossAttention(nn.Module): |
简单来说,就是通过Q.K的平均值-Q.K的方差计算得出一个score,这个score就是确定性分数,方差是惩罚项,表示不确定。把这个score作为V的权重,最终得到这一模块的计算值。
1 | scores = mean_scores - self.beta * torch.sqrt(var_penalty) # attention map,方差越大,score越小。 |
用于PVL Adapter中部的特征融合,键Keys和值Values建模为具有可学习均值和方差的概率分布,以纳入其中的不确定性。
1 | # 这是V_sample部分 |
V_sample把原本的V点转换为了一个分布。即均值+方差*(0,1)的随机数。
1 | gate = torch.sigmoid(self.gate) |
最后一个门控输出,是原Q值和加权后得出的q的加权和。
loss
1 | # Compute logits |
Soft Contrastive Loss
使用的soft_targets是各个文本的相似性矩阵,表示相似的标签,虽然这两个词不一样,但它们很像。如果两个文本描述(例如“肿瘤”和“恶性肿块”)语义相近,它们的相似度就会很高;而以往CLIP模型没有这个运算,标准
CLIP 假设 Batch
内的图文对是唯一的正样本,其余均为负样本,目标分布 ( Y*Y*
):单位矩阵(对角线为 1,其余为 0)。 LsoftCon = −∑i∑jSijlogPij

再加上分割loss就是最终的loss,其中Seg loss属于常规写法,没有进行改动。
1 | # Seg loss |
实验
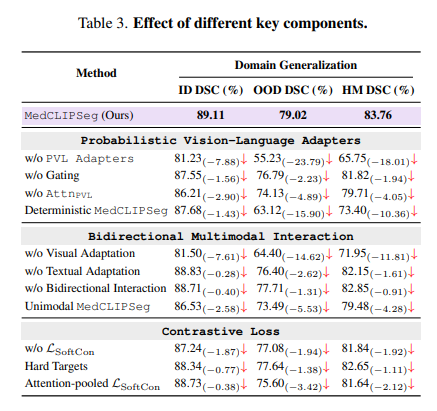
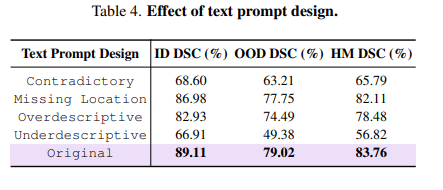
左图为消融实验,右图为不同text数据集(矛盾/缺失位置/过描述/不足描述/原始数据)下的数据。
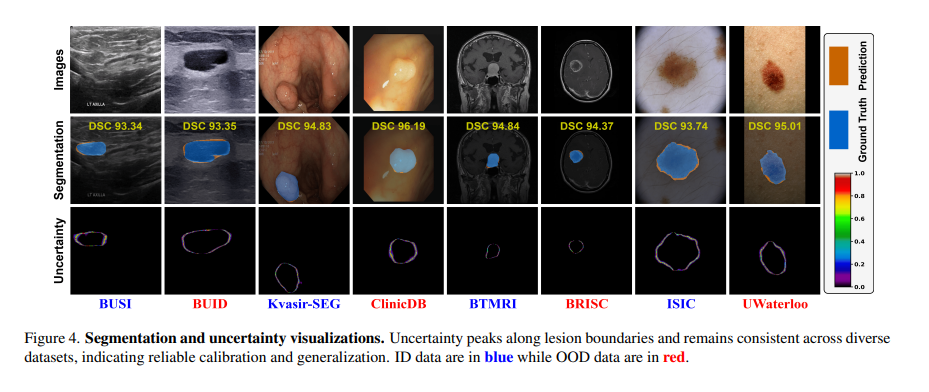
总结
实际上是在讲如何让 AI 学会“犹豫”。通过 PVL Adapter,MedCLIPSeg 将 CLIP 强大的图文匹配能力与贝叶斯深度学习的严谨性结合在一起,使其不仅能完成分割任务,还能实时评估任务的可信度。
PVL Adapter 是 MedCLIPSeg 的“安全阀”和“增强器”。它让 CLIP 在处理高难度的医学图像时,不仅拥有了双向理解的能力,更重要的是拥有了“自我怀疑”的能力——这种能力在医疗诊断中比单纯的准确率更珍贵。




