MapLe
MaPLe:Multi-model Prompt Learning
多模态提示学习
- 来源:[CVPR 2023] Official repository of paper titled “MaPLe: Multi-modal Prompt Learning”.
- 作者是印度人
- 代码:https://github.com/muzairkhattak/multimodal-prompt-learning
背景
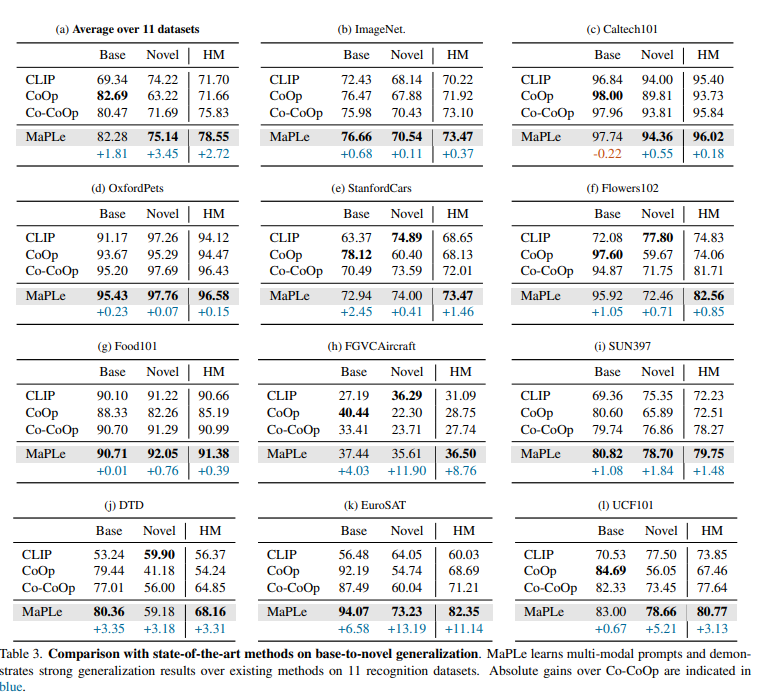
预训练的视觉语言模型如CLIP在下游任务中表现出优异的泛化能力,然而,它们对输入文本的Prompt非常敏感,需要仔细选择Prompt templates提示模板才能表现良好。
受到自然语言处理文献的启发,最近的CLIP适应方法将提示作为文本输入来微调CLIP应对下游任务。在CLIP的一个分支(文本-图像)中使用Prompt是次优的,因为不允许在下游任务中动态调整两个表示空间。
在少样本的情况下对模型进行微调是不现实的,甚至会导致模型以往预训练的信息。Prompt方法可以避免手动调整templates,并不需要调整原始参数。这对于CLIP是未被充分研究的课题。
motivation
来源于CLIP的多模态特性,文本和图像编码器共存的双塔结构,两者都对正确对齐视觉-语言模态起作用。仅针对CLIP中的文本模态进行Prompt Learning是不够的。
具体实施方法
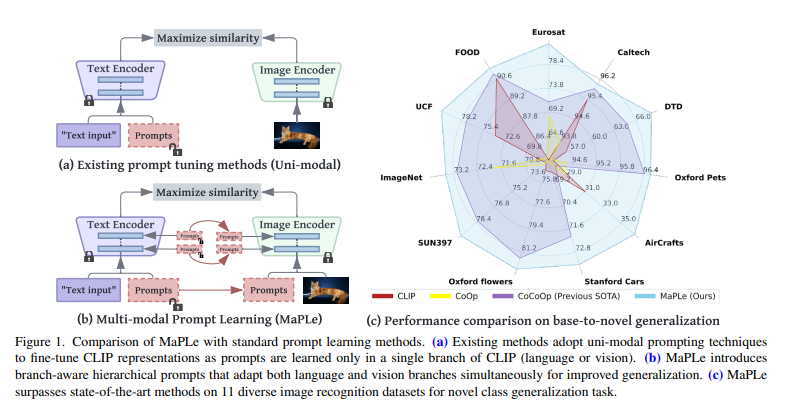
如上图,作者认为,以往方法中只给Text分支Prompts是不够的,只有通过一个函数,把生成的Prompt同时给到两个分支,才是合理的,输入的Prompt还是原本的文字信息。其实不是什么很复杂的东西,作者写的很复杂。
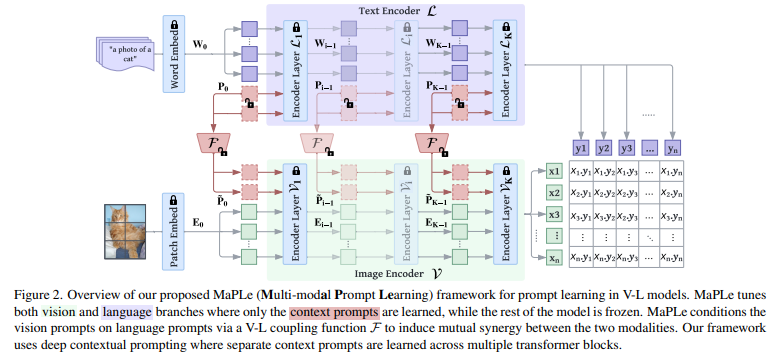
MaPLe (Multi-modal Prompt Learning) 是一种针对视觉-语言模型(如CLIP)的高效微调方法,旨在通过多模态提示学习来更好地适应下游任务。
它的核心思想是:同时在视觉和语言两个分支中引入可学习的提示(Prompts),并通过一个耦合函数将它们紧密联系起来,以实现两种模态的协同优化。
🎯 动机:为什么需要 MaPLe?
以CLIP为代表的视觉-语言模型虽然在下游任务上展现出强大的泛化能力,但其性能高度依赖于输入文本提示(Prompt)的设计。
- 现有方法的局限:早期的提示学习方法(如CoOp)仅在文本分支引入可学习的参数来替代人工设计的提示。然而,作者认为这种单模态的调整是次优的,因为它无法灵活地动态调整视觉和语言两个表示空间,限制了模态间的交互和对齐。
- MaPLe的解决方案:为了让模型在下游任务上达到最佳对齐,提示学习应该更完整地适应整个模型。因此,MaPLe提出同时在视觉和语言分支进行提示学习,并通过一个耦合机制确保两者协同工作。
⚙️ 方法:MaPLe 如何工作?
MaPLe 的方法可以分解为三个关键部分:
- 深度语言提示 (Deep Language Prompting) 在文本编码器的前 J 层Transformer模块中,分别引入可学习的提示标记(learnable tokens)。这些提示会与原始的文本输入嵌入(如 “a photo of a [CLASS]”)拼接在一起,逐层输入。这使得模型能够学习到更深层次的、与上下文相关的语言特征。
- 深度视觉提示 (Deep Vision Prompting) 与语言分支类似,在图像编码器的前 J 层Transformer模块中,也分别引入可学习的提示标记。这些提示会与图像的块嵌入(patch embeddings)拼接,从而在视觉特征提取的早期阶段就注入可学习的上下文信息。
- 视觉-语言提示耦合 (Vision-Language Prompt Coupling)
这是 MaPLe
的核心创新。为了让两个分支的提示产生协同效应,而不是独立学习,作者设计了一个耦合函数
(Coupling Function)。
- 具体实现:该函数通常是一个简单的线性层。它将语言分支的提示作为输入,通过映射来生成视觉分支的提示。
- 作用:这个耦合函数充当了两种模态之间的桥梁,使得梯度可以在视觉和语言提示之间相互传播,从而鼓励它们共同学习,实现对两种模态表示的协同调整。
在整个微调过程中,只有这些可学习的提示参数和耦合函数会被更新,而预训练的CLIP模型主体参数则被冻结,这使其成为一种参数高效的微调方法。
具体代码实现片段
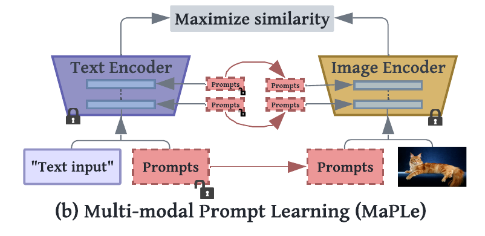
这一张图看的比较清晰一些。可见,原CLIP的基座模型Text Encoder以及Image Encoder均为不可学习参数,不参与参数优化步骤。只有Prompts块中的参数进行学习优化。
1 | prompts, shared_ctx, deep_compound_prompts_text, deep_compound_prompts_vision = self.prompt_learner() |
通过代码段理解这个算法,就是
先通过
prompt_learner函数得到4个Prompt分量。TEXT部分原输入tokenized_prompts,加入两个输入tokenized_prompts, deep_compound_prompts_textVISION部分原输入image,加入两个输入shared_ctx, deep_compound_prompts_vision只不过是在过程中进行了一些堆叠,进行融合了而已。从代码看,只有输入的这一块有
Prompts输入,中间部分的Text Encoder以及Image Encoder之间的Prompts是没有的。Coupling模块似乎没有找到,通过
self.prompt_learner()函数同时经过某些操作一起生成的这个步骤就是Coupling。强制了视觉提示必须包含语言提示的信息。